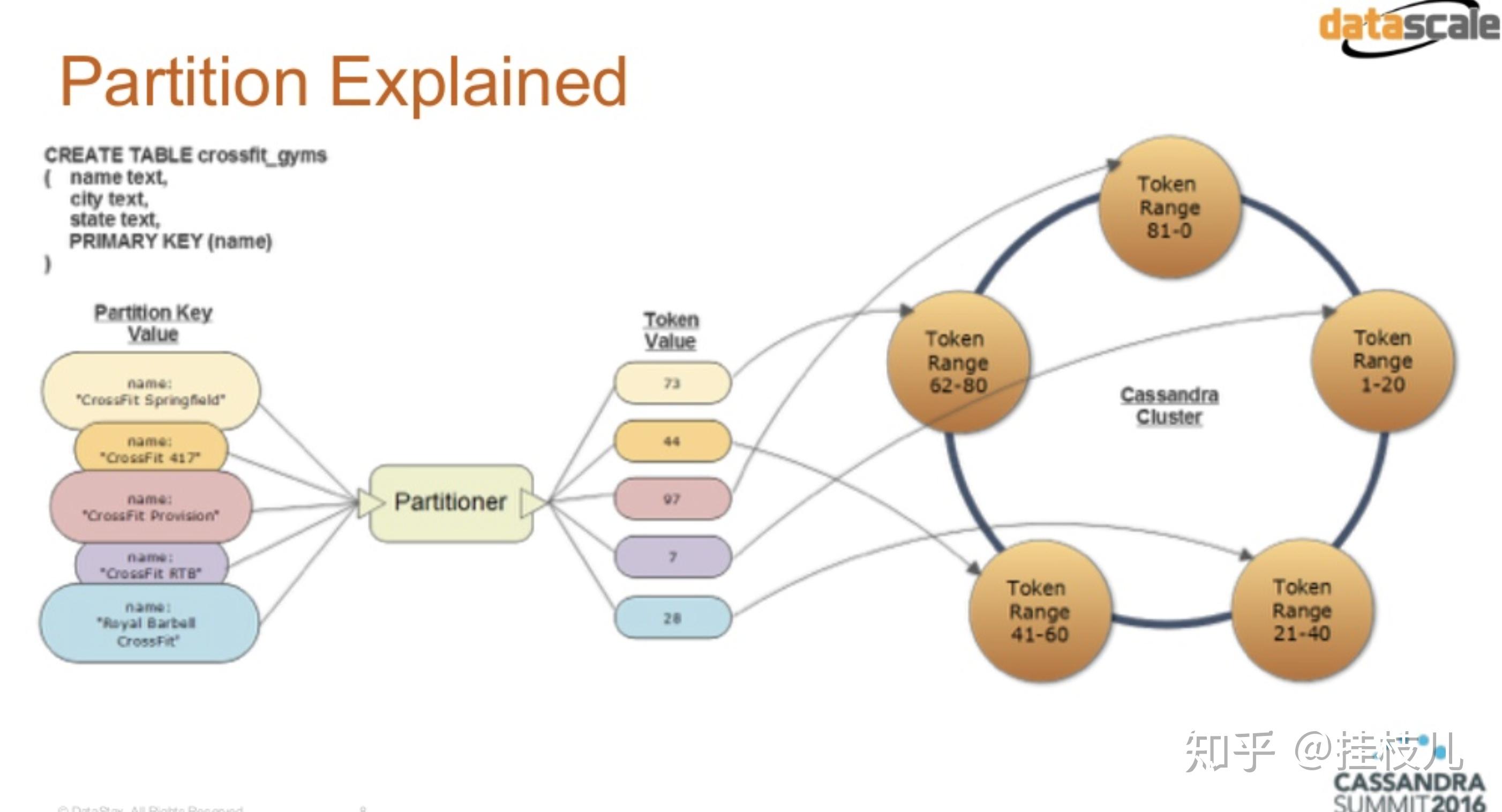
Cassandra Partition Key And Sort Key. Basically, a partitioner is a hash function to determine the token value by hashing the partition key of a row’s data. In our example crossfit_gyms_by_location table, country_code is the. The hash value of partition key is used to determine the specific node in a cluster to store the data. in general, the first field or component of a primary key is hashed to generate the partition key and the remaining fields or components are the. the partitioner determines how data is distributed across the nodes in a cassandra cluster. in such a case the first part of the primary key is called the partition key (pet_chip_id in the above example) and. a clustering key is responsible for sorting data within the partition. Then, this partition key token is used to determine and distribute the row data within the ring. each cassandra table has a partition key which can be standalone or composite. The partition key determines data locality through. let’s have a look at a few possible cql schema definitions, to get an idea of how the primary key is formed.
from zhuanlan.zhihu.com
the partitioner determines how data is distributed across the nodes in a cassandra cluster. The partition key determines data locality through. in such a case the first part of the primary key is called the partition key (pet_chip_id in the above example) and. each cassandra table has a partition key which can be standalone or composite. In our example crossfit_gyms_by_location table, country_code is the. The hash value of partition key is used to determine the specific node in a cluster to store the data. in general, the first field or component of a primary key is hashed to generate the partition key and the remaining fields or components are the. a clustering key is responsible for sorting data within the partition. Basically, a partitioner is a hash function to determine the token value by hashing the partition key of a row’s data. let’s have a look at a few possible cql schema definitions, to get an idea of how the primary key is formed.
啊,Cassandra —— 简介,安装,建表 知乎
Cassandra Partition Key And Sort Key in such a case the first part of the primary key is called the partition key (pet_chip_id in the above example) and. The partition key determines data locality through. a clustering key is responsible for sorting data within the partition. In our example crossfit_gyms_by_location table, country_code is the. The hash value of partition key is used to determine the specific node in a cluster to store the data. Then, this partition key token is used to determine and distribute the row data within the ring. Basically, a partitioner is a hash function to determine the token value by hashing the partition key of a row’s data. in general, the first field or component of a primary key is hashed to generate the partition key and the remaining fields or components are the. each cassandra table has a partition key which can be standalone or composite. let’s have a look at a few possible cql schema definitions, to get an idea of how the primary key is formed. the partitioner determines how data is distributed across the nodes in a cassandra cluster. in such a case the first part of the primary key is called the partition key (pet_chip_id in the above example) and.